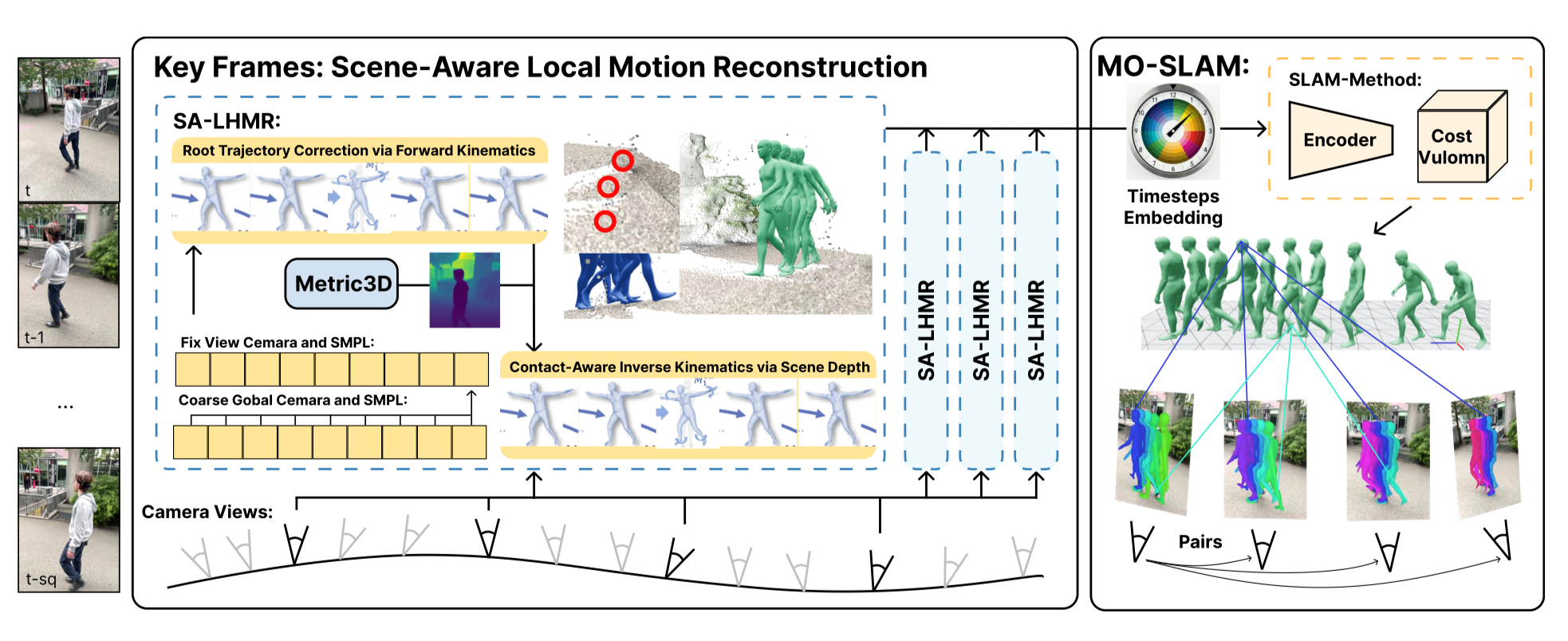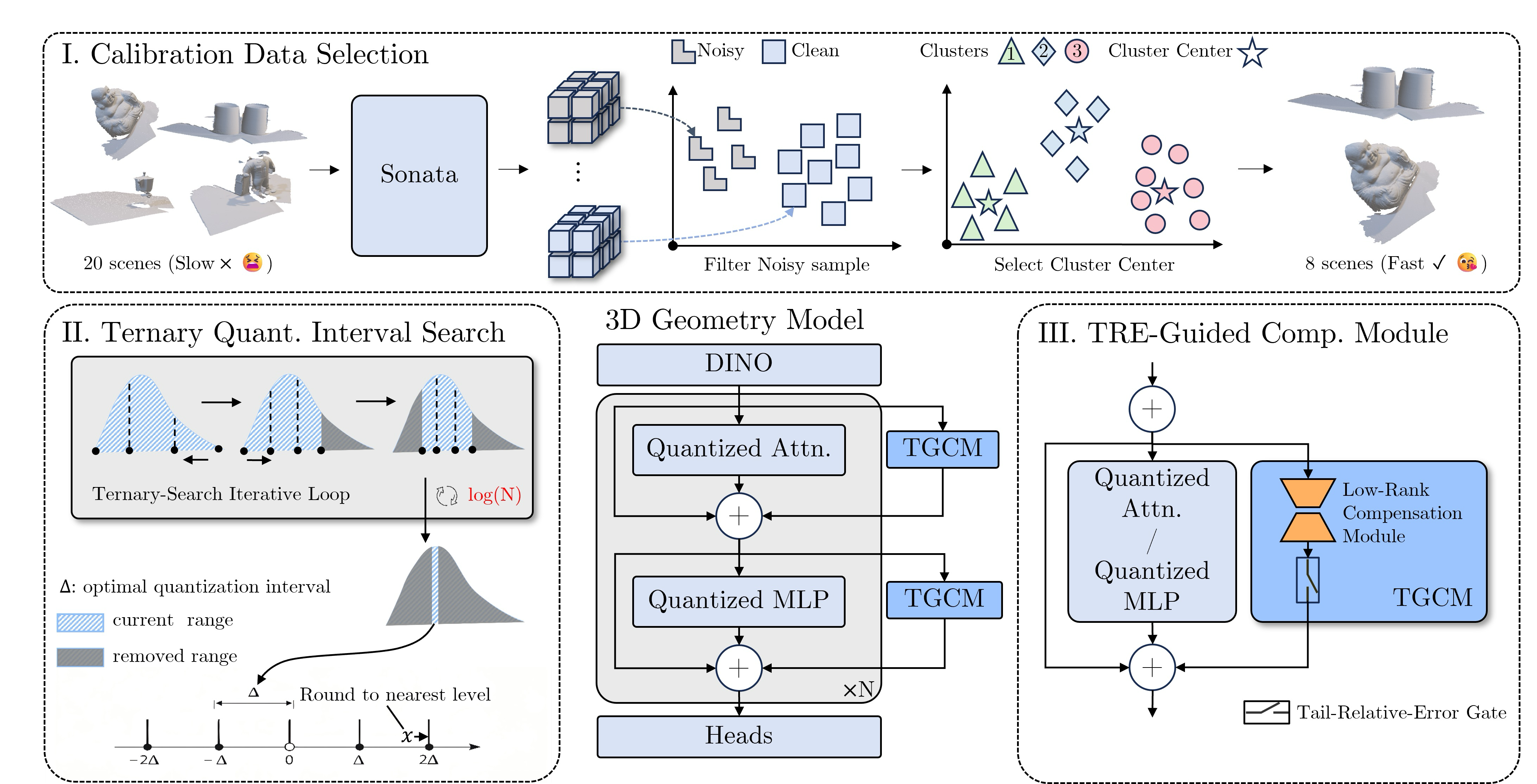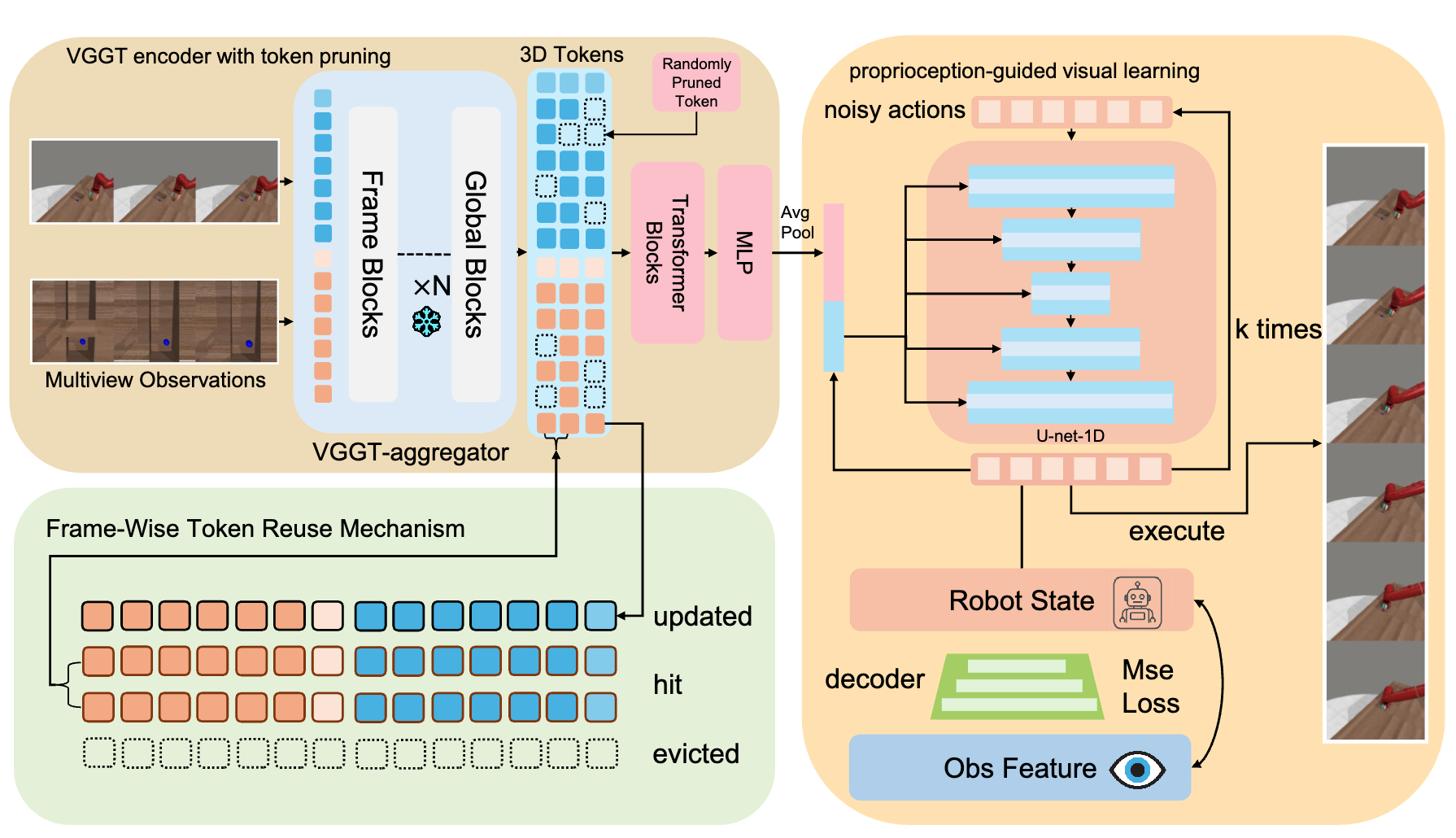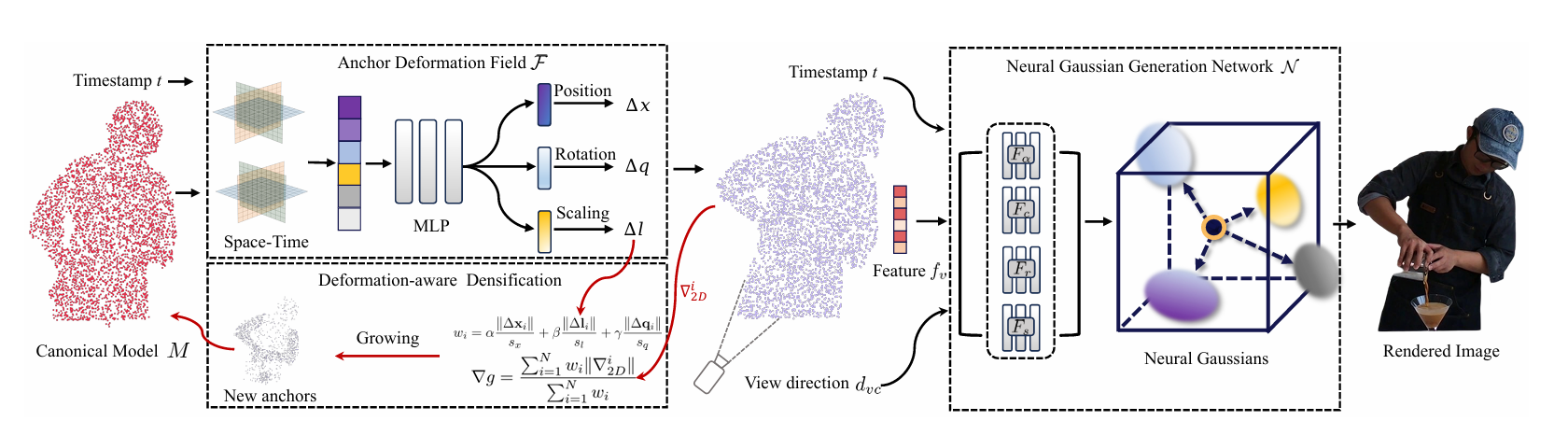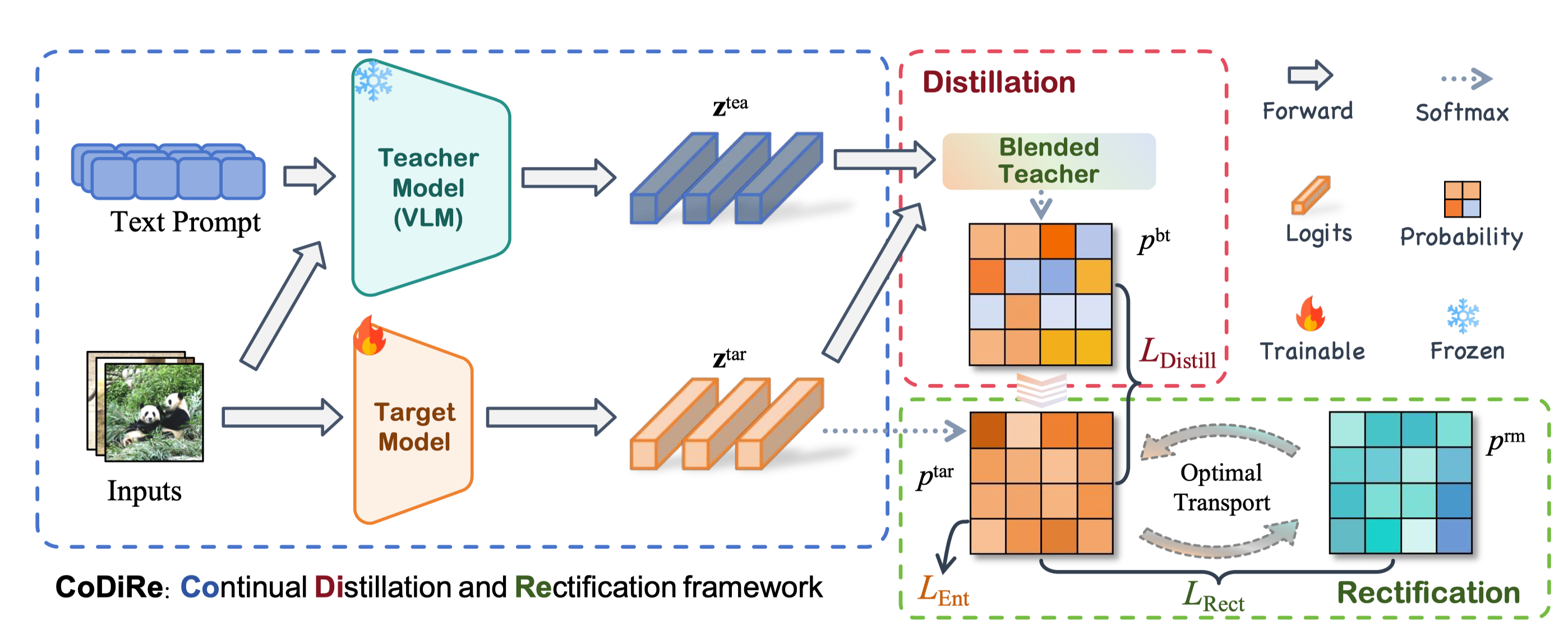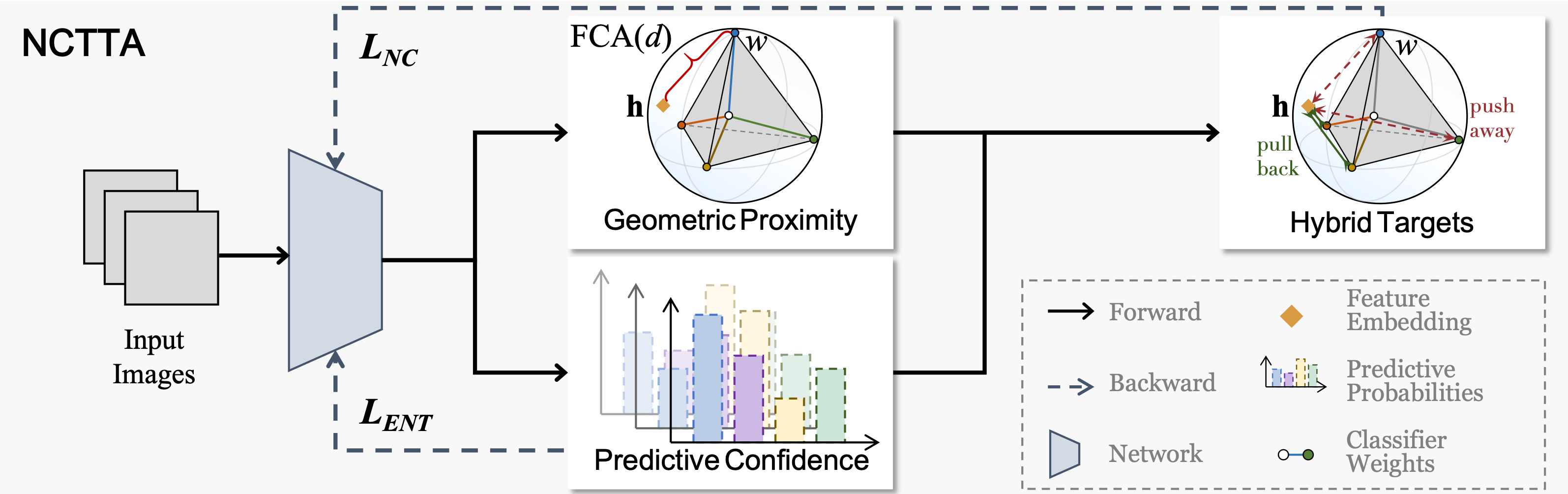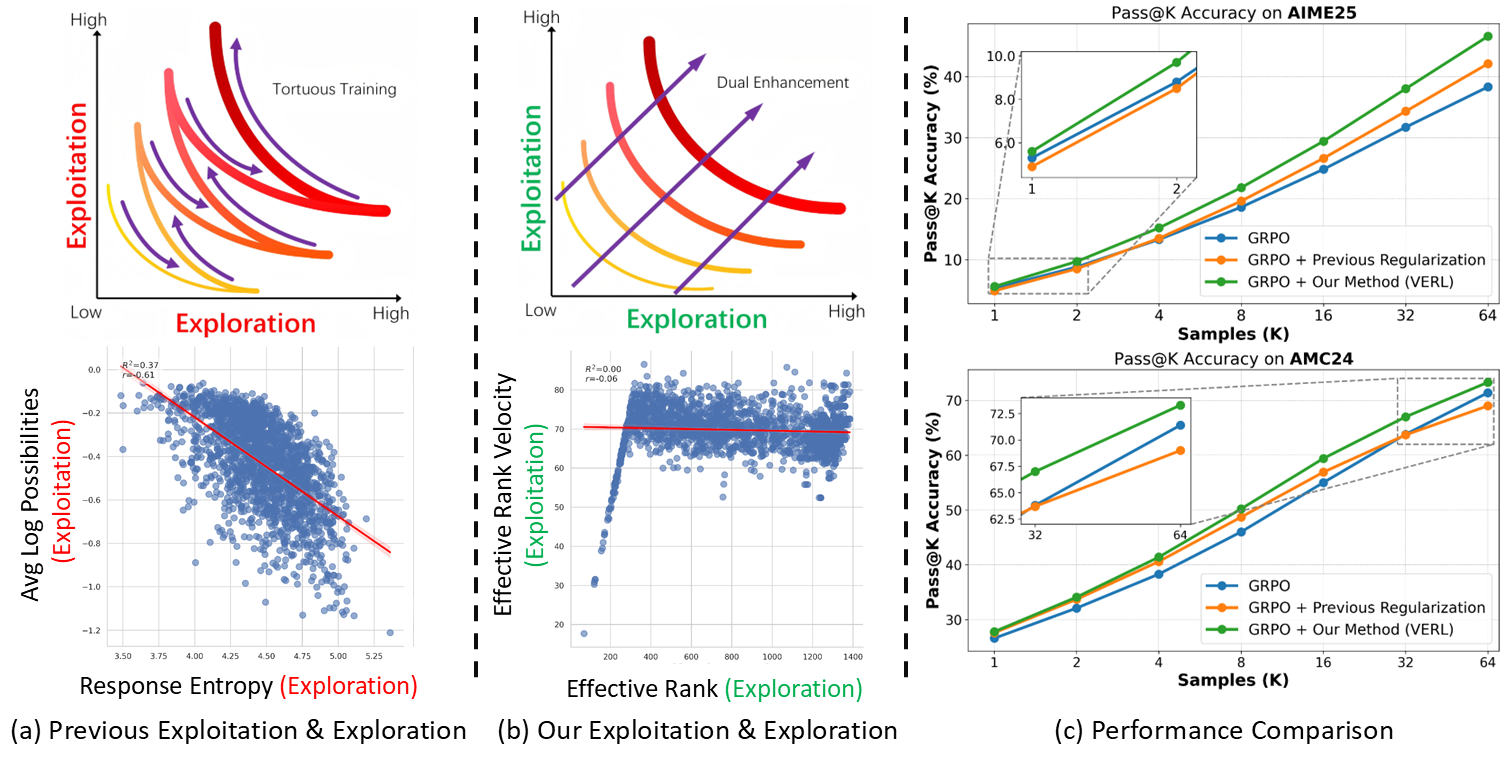
AnchorGen: Multi-View Geometric Anchoring for Keyframe-Aware Embodied Video Generation
Preprint · Under Review预印本 · 投稿中
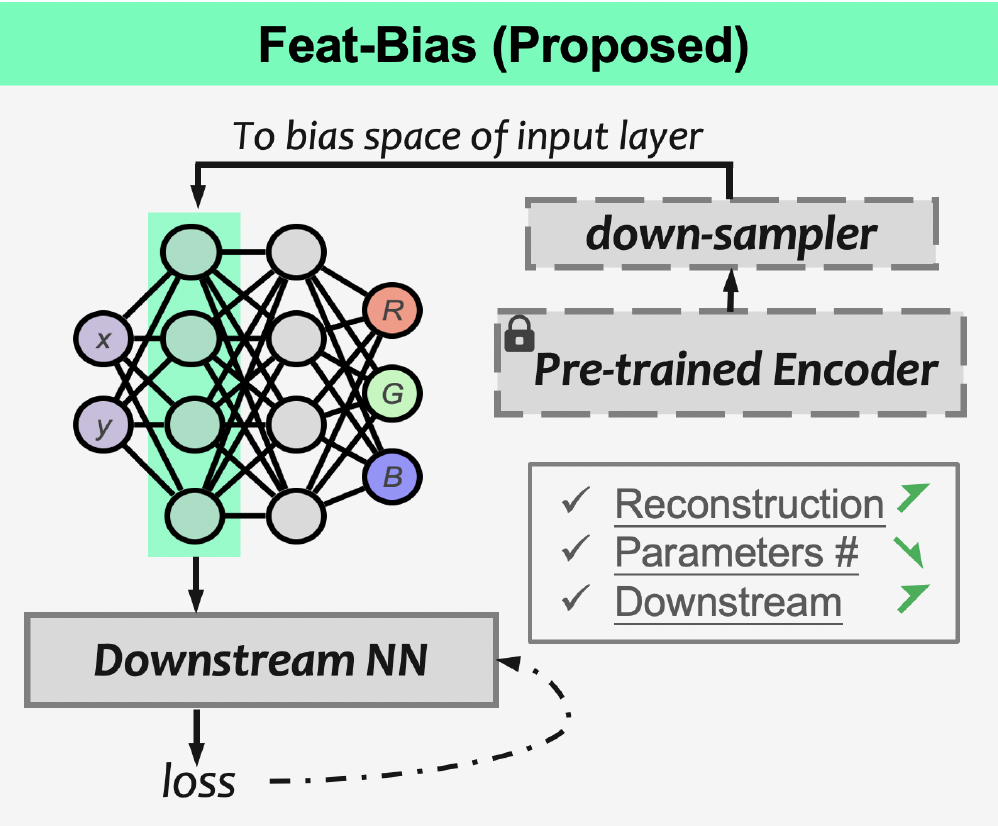
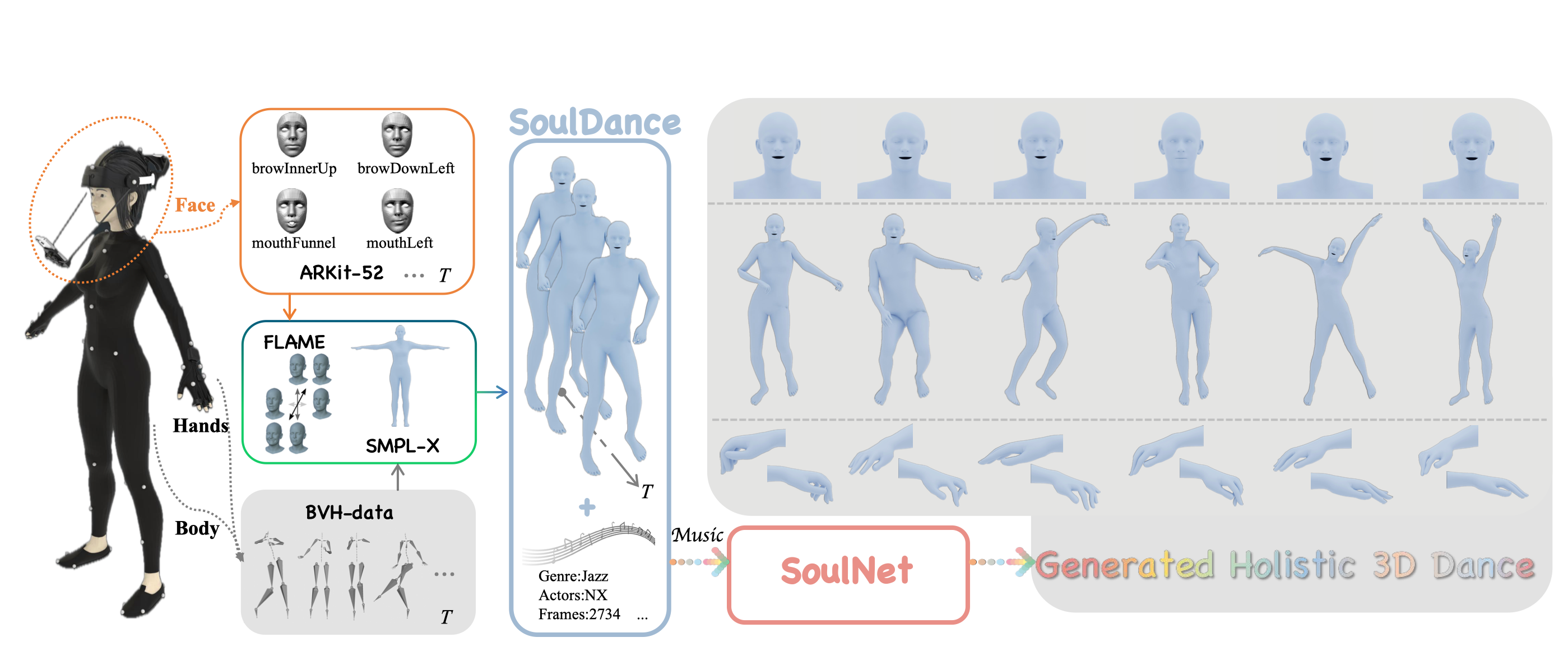
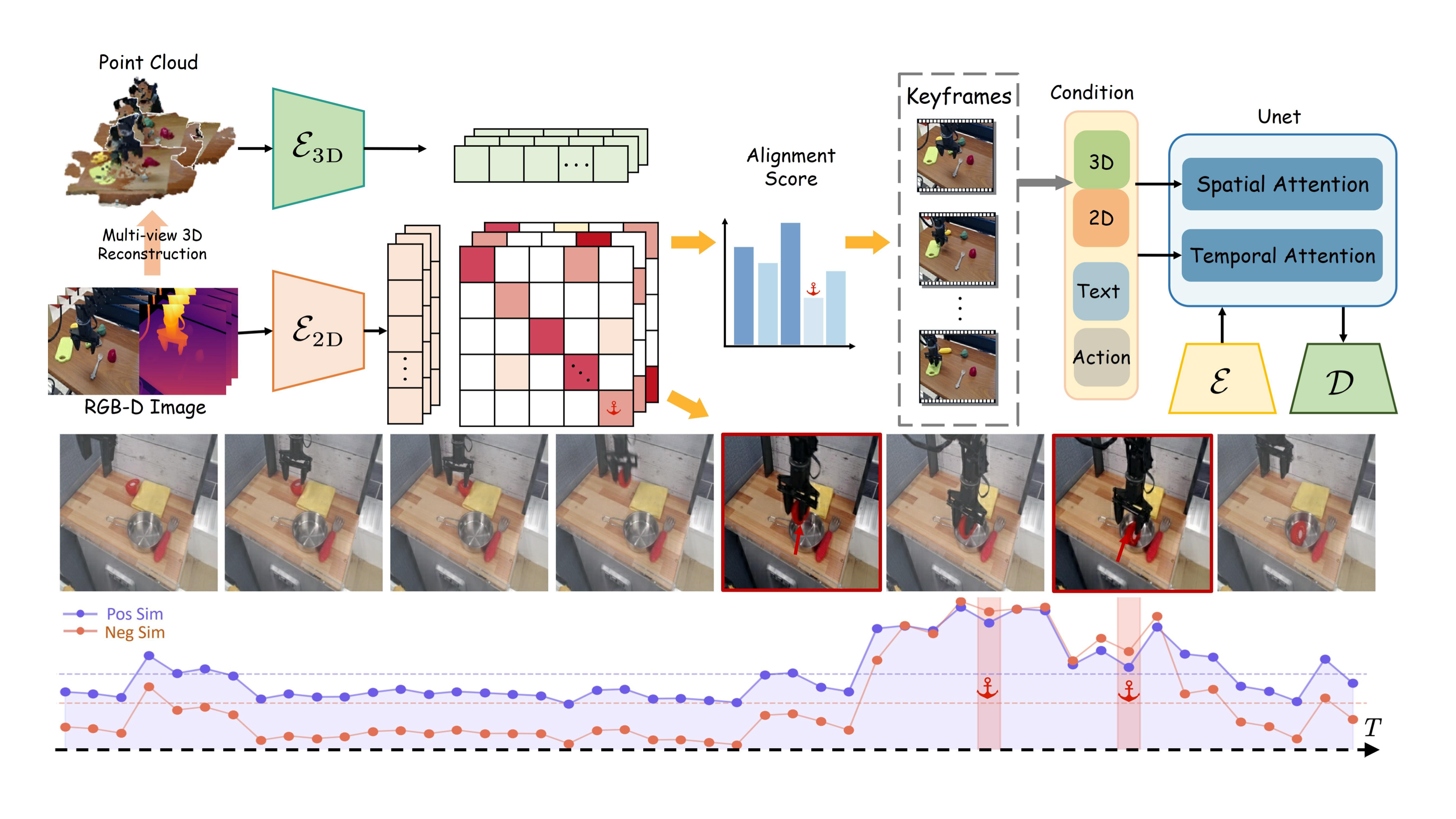
AnchorGen 是一种关键帧感知的几何锚定视频生成框架,用于提升机器人动作条件视频的三维一致性。方法通过自监督二维-三维对比学习自动发现接触与状态变化等重要关键帧,并以稀疏几何特征作为结构化条件注入多模态扩散模型,在真实机器人数据上显著提升生成质量与空间一致性。